python으로 네이버 블로그 검색 api 활용하기2 json으로 데이터 사용하기
- programming/Python
- 2020. 8. 30. 22:03

2020/08/30 - [programming/Python] - python으로 네이버 블로그 검색 api 활용하기!
python으로 네이버 블로그 검색 api 활용하기!
안녕하세요. 홍지군입니다. 최근 python을 배우기 시작해서 쿠팡 파트너스api와 웹 크롤링을 통해서 얼마전 만든 개인 홈페이지와 네이버 블로그에 html소스를 자동으로 업로드 하는 프로그램을 만
swpfun.tistory.com
안녕하세요. 홍지군입니다.
이전 글에서는 python에서 네이버 블로그 api 검색에 대해서 기본적으로 값을 받아오는 것 까지 해봤습니다. 이번에는 json으로 값을 변환하고 변환된 json 배열값을 하나하나 뽑아서 출력해보는 시간을 가져보겠습니다
import os
import sys
import urllib.request
import json
client_id = "" # <- 발급받은 client id
client_secret = "" # <- 발급받은 client secret
encText = urllib.parse.quote('swpfun') # <- search keyword
url = "https://openapi.naver.com/v1/search/blog?query=" + encText # json 결과
# url = "https://openapi.naver.com/v1/search/blog.xml?query=" + encText # xml 결과
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
rescode = response.getcode()
if(rescode==200):
response_body = json.dumps(json.load(response),indent=4, ensure_ascii=False)
print(response_body)
# response_body = response.read()
# print(response_body.decode('utf-8'))
else:
print("Error Code:" + rescode)
if(rescode==200): 소스코드 밑에 기존에 있던 소스코드 앞에 #으로 주석처리 해주고 아래 있는 소스를 추가하여 줍니다.
response_body = json.dumps(json.load(response), indent=4, ensure_ascii=False)
print(response_body)

소스코드를 수정하고 실행해보면 위에 사진과 같이 결과 값이 보기좋게 정렬되어 출력되는 것을 확인해볼 수 있습니다.
json.dumps()옵션에 대해서는 python 사용설명서에서 추가적인 내용을 확인해 볼 수 있습니다.
python.flowdas.com/library/json.html?highlight=dumps#json.dumps
json --- JSON 인코더와 디코더 — 파이썬 설명서 주석판
json --- JSON 인코더와 디코더 소스 코드: Lib/json/__init__.py flowdas 이 페이지에서는 JSON 문서의 {} 리터럴을 가리키기 위해 "오브젝트"라는 표현을 사용하고 있습니다. "객체"는 파이썬 객체를 가리키��
python.flowdas.com
제가 사용한 indent와 ensure_ascii=False에 대해서만 간략하게 정리하고 넘어가겠습니다.
indent 옵션
indent 옵션은 공백제어 옵션으로 indent=1 로 설정하면 공백을 1개 넣어 결과값이 보여지게 되는데 가장 눈에 잘 들어오는 json 형식은 3~4정도가 가장 보기 좋게 정렬되어지는 것 같습니다.
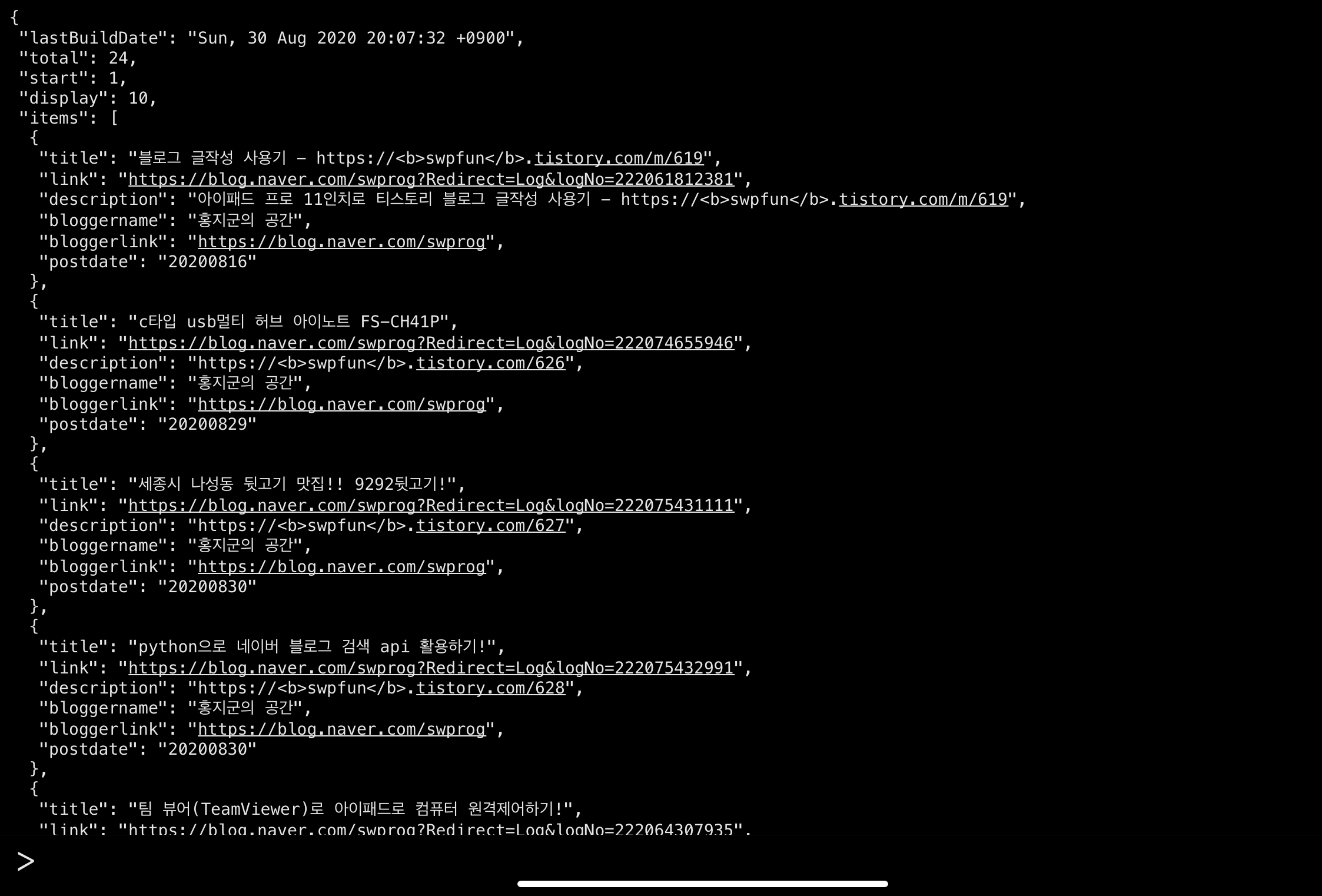
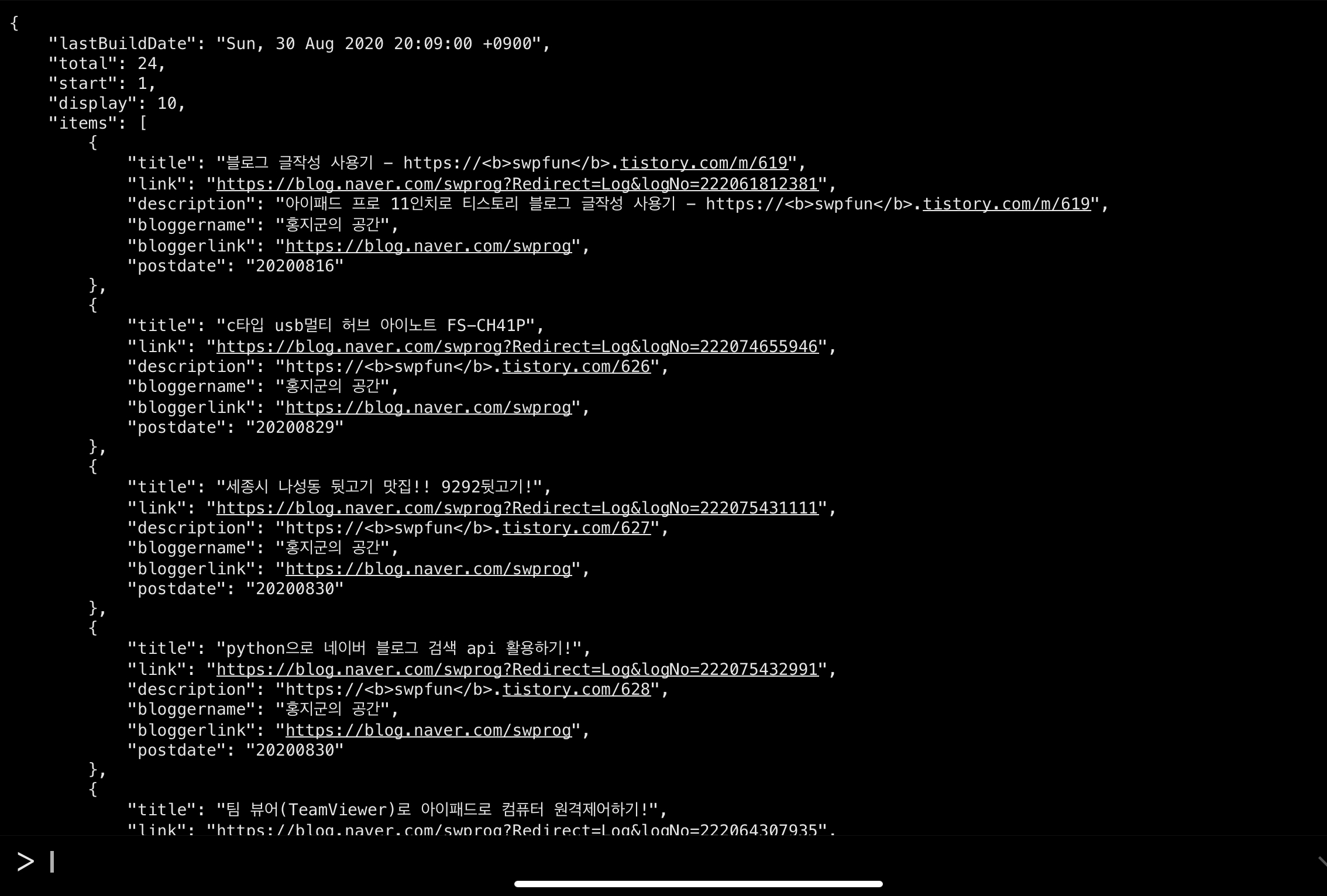
왼쪽은 indent=1 옵션을 넣은 결과물이고 오른쪽은 indent=4를 넣은 결과물 입니다. "items"는 1depth 이고 하위 depth로 title과 link 등등 있는데 depth에 따라서 정보를 한눈에 쉽게 확인할 수 있도록 해줍니다.
ensure_ascii=False 옵션


왼쪽은 ensure_ascii=False 옵션을 넣지 않은 결과값이고 오른쪽은 ensure_ascii=False 옵션을 넣은 결과값입니다. 차이 점을 보면 옵션을 넣지 않은 왼쪽사진의 결과값에는 \ud0c0 처럼 아스키코드처럼 데이터가 보여지는데 ensure_ascii=False 옵션을 넣으면 아스키코드값이 아닌 정상적인 문자로 읽기 좋게 보여지게 됩니다.
이제 데이터를 콘솔에서 보기좋게 출력하는 방식으로 읽어봤습니다. 이번에는 데이터를 하나하나 끄집어 내어 사용해보겠습니다.

콘솔에 찍힌 결과를 한번 확인해보겠습니다. 첫번째 가장 상위에 위치하는 데이터들은 lastBuildDatem, total, start, display, items 의 항목들이 있습니다.

소스 코드를 다음과 같이 수정합니다.
response_body = json.load(response) 이렇게 되면 json 형식의 배열로 response_body에 데이터가 대입되어 배열의 형태로서 데이터들을 추출할 수 있게 됩니다.

이전 결과와 비교하면 print(response_body['items']) 항목은 1차 배열 속에 있는 배열입니다. items의 항목을 뽑기 위해서는 response_body['items'][0] 으로 하면 items 밑에있는 0번째 항목만을 출력할 수 있게됩니다.

0번째 항목을 출력해왔고 이제 속에 있는 'title'과 'link' 그리고 'description'등등을 뽑기위해서는 어떻게 해야할까요??
response_body['items'][0]['title']형식으로 뽑아올 수 있습니다.


print(response_body['items'][0]['title']) 처럼 response_body['items'][0]['title']을 변수에 하나씩 담아서 사용할 수 있습니다.
'programming > Python' 카테고리의 다른 글
| python독학중!! GUI 화면띄우기 (tkinter) (1) | 2020.09.15 |
|---|---|
| 파이썬 (PyQt5 모듈, Pandas 모듈) exe 용량문제..고민중... (1) | 2020.08.31 |
| python으로 네이버 블로그 검색 api 활용하기! (2) | 2020.08.30 |
| 파이썬(Python)으로 쿠팡 파트너스 API활용하기 3 (4) | 2020.08.16 |
| 파이썬(python)으로 쿠팡 파트너스 API 활용하기2 (1) | 2020.08.16 |



